Een gids voor sentimentanalyse: Wat is het en hoe werkt het?


Samenvatting van het artikel
Veel pro's waarschuwen dat negatief sentiment de zakelijke reputatie van uw merk op het web schaadt. Lees deze gids om te begrijpen wat het werkelijk is, hoe sentimentanalyse werkt en of u het moet gebruiken.
20 minuten lezen
Sentimentanalyse is het ultieme modewoord. En zoals dat gaat met modewoorden, is het een concept dat vaak verkeerd begrepen wordt.
Bij Awario bieden we een systeem voor merksentimentanalyse, en we krijgen veel vragen over sentiment sinds we het hebben uitgebracht.
Met een beetje geluk helpt deze gids u meer te begrijpen van sentimentanalyse: van hoe het wordt gebruikt tot de ins en outs van de mechanica en NLP-technieken erachter.
Laten we beginnen met de olifant van een vraag:
Wat is sentimentanalyse?
Sentimentanalyse, ook wel opinion mining genoemd, is het proces van het bepalen van de emotie (vaak ingedeeld als positief sentiment, negatief of neutraal) die door iemand ten aanzien van een onderwerp of verschijnsel wordt geuit.
In de context van social listening en online reputatiemanagement wordt het analyseren van sentiment meestal gebruikt om de stem van de klant vast te leggen en de houding van consumenten ten opzichte van een merk, bedrijf, product of persoon te bepalen.
Hoe wordt sentimentanalyse gebruikt?
Sentimentanalyse is misschien wel het belangrijkste wat u in een social listening tool moet zoeken. Van het analyseren van de gezondheid van een merk tot het verbeteren van de klantenservice, hier zijn enkele van de belangrijkste dingen waar tools voor sentimentanalyse u bij helpen.
1. Bewaak de gezondheid van het merk
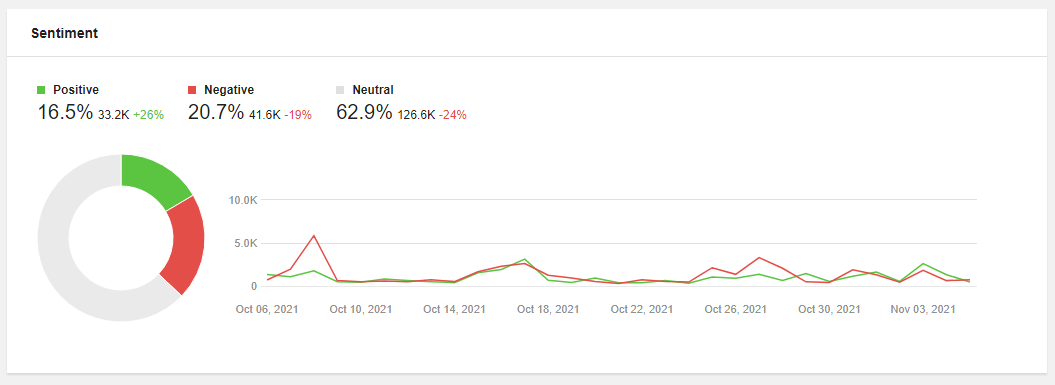
Sentimentanalyse is een belangrijk onderdeel van het bewaken van uw merk en het beoordelen van de gezondheid van uw merk. Houd in uw social media monitoring dashboard de verhouding tussen positieve en negatieve vermeldingen binnen de conversaties over uw merk in de gaten en kijk naar de belangrijkste thema's binnen zowel positieve als negatieve feedback om te leren waarover uw klanten het meest loven en klagen.

2. Spot reputatiecrises vroegtijdig
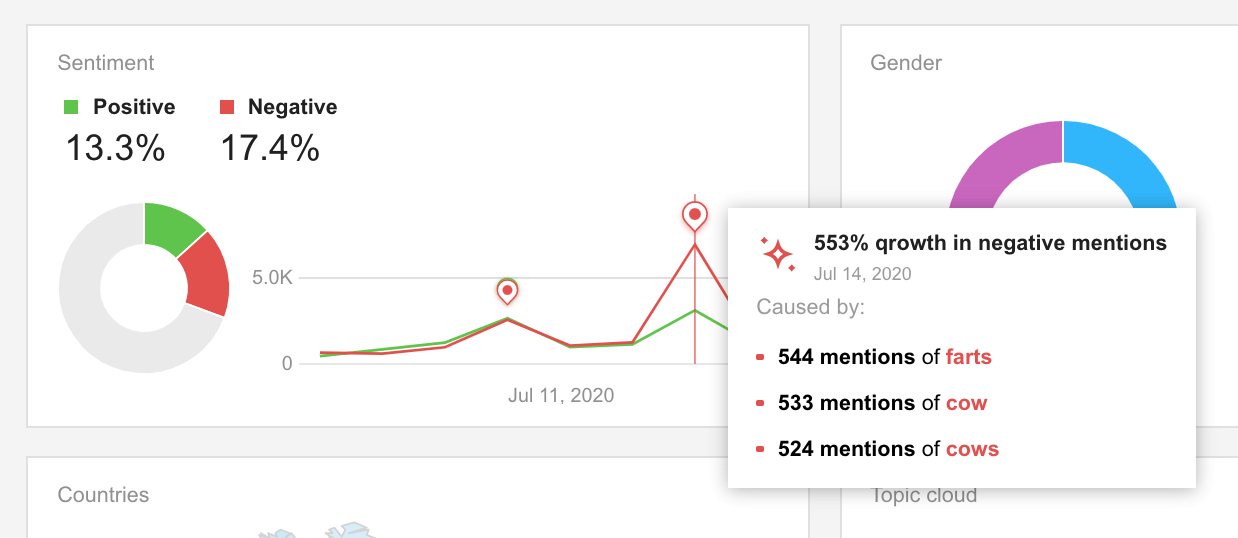
Sentimentanalyse wordt niet alleen gebruikt voor social media-analyse en -rapportage. Het is net zo belangrijk om dagelijks in te loggen op uw social listening dashboard en te letten op pieken in negatieve vermeldingen - op die manier kunt u een reputatiecrisis vroegtijdig ondervangen en voorkomen dat het een regelrechte ramp wordt.
In Awario kunt u met behulp van Insights ook de redenen begrijpen achter eventuele pieken in het volume van negatieve of positieve conversaties. Door op deze inzichten te klikken, kunt u dieper graven in historische en real-time gegevens en zien wat de oorzaak was van de toestroom van negatieve (of positieve) vermeldingen.
Een grondige sentimentanalyse kan de reputatie van uw merk redden wanneer de negatieve vermeldingen ervan op het web in een alarmerend tempo toenemen. Het helpt u ook de wortels van positieve en negatieve prestaties te identificeren.
Door me aan te melden ga ik akkoord met de gebruiksvoorwaarden en het privacybeleid.
3. Prestaties van campagnes bijhouden
Op dezelfde manier waarop u uw merk bewaakt, kunt u vermeldingen bijhouden van uw marketingcampagnes, samenwerkingen, evenementen die u organiseert, of letterlijk elk ander initiatief van uw bedrijf dat online buzz genereert.
Net als bij merkmonitoring kunt u sentimentanalyse gebruiken om het algemene sentiment rond de campagne te meten en op zoek te gaan naar pieken om de redenen daarachter te achterhalen. Nog even snel: Awario biedt meertalige sentimentanalyse, zodat u kunt volgen hoe uw campagne over de hele wereld werkt.
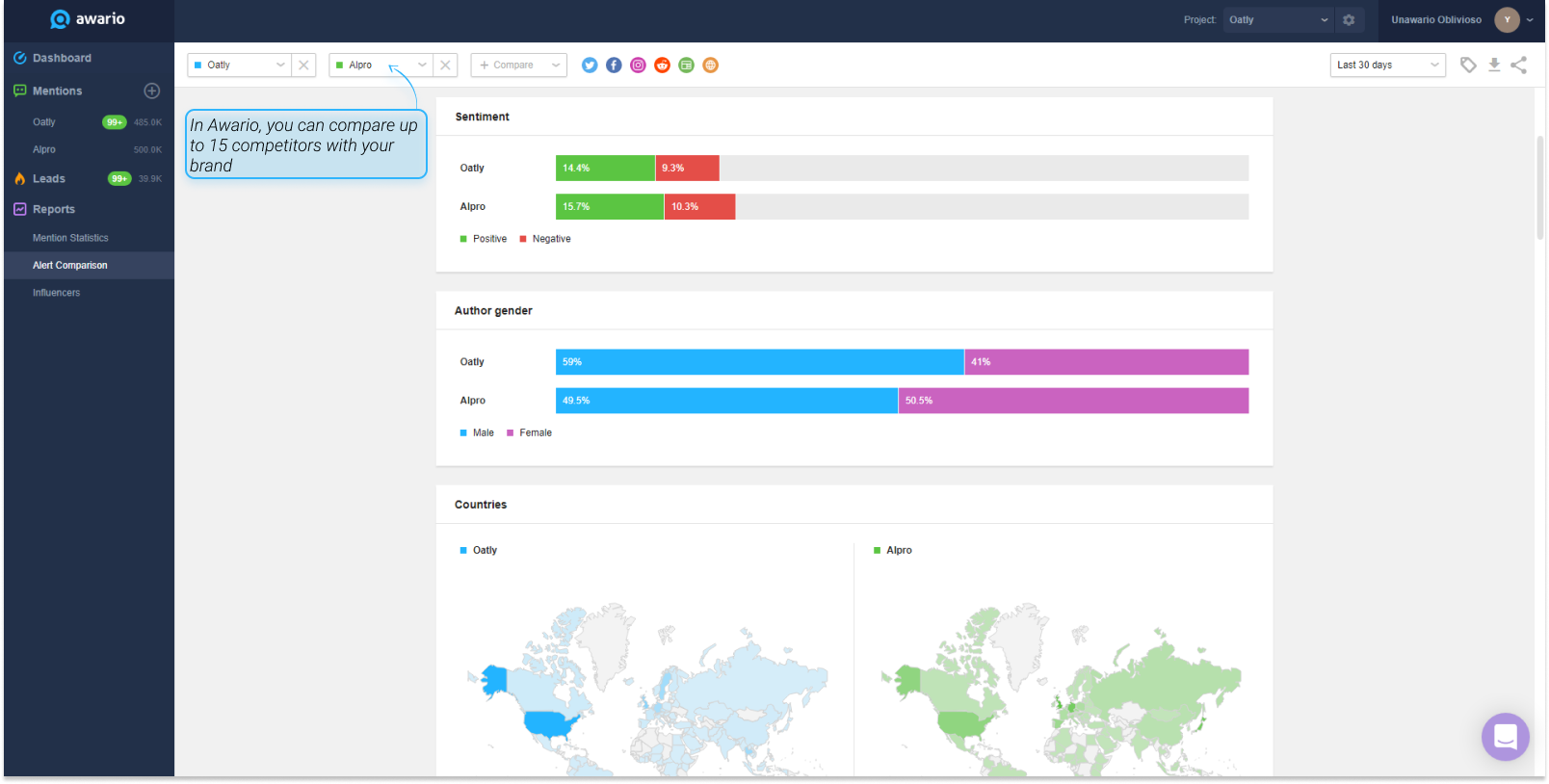
4. Concurrentieanalyse uitvoeren
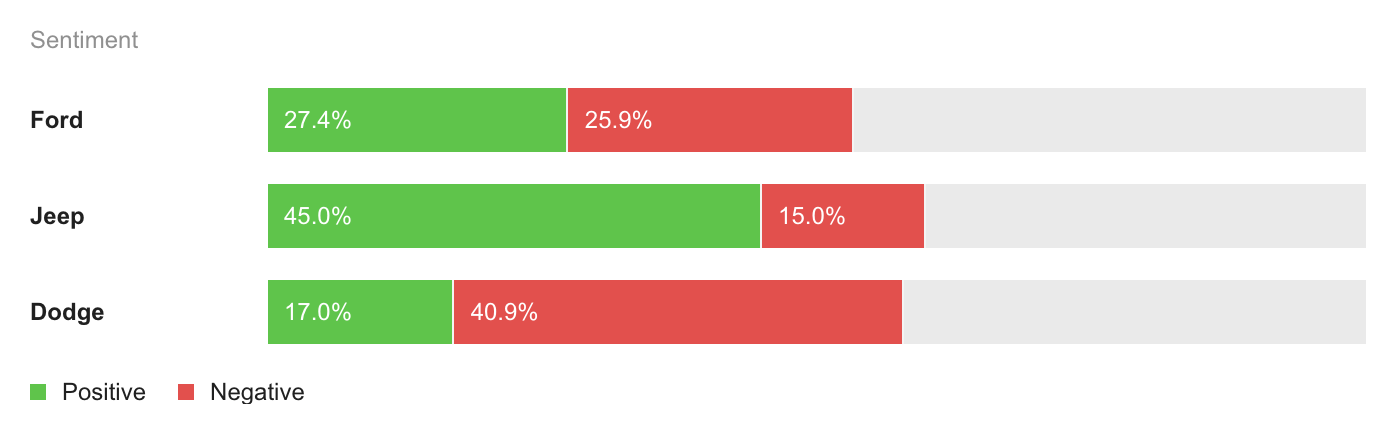
Door het sentiment van je concurrenten te volgen, kun je zien over welke aspecten van hun producten klanten het meest (en minst) enthousiast zijn. Bovendien kan het sentiment van concurrenten ook als benchmark dienen wanneer u het sentiment achter de vermeldingen van uw eigen merk en product analyseert.
Stel, 50% van uw vermeldingen zijn positief, 40% zijn negatief, en de rest is neutraal. Hoe weet je of dat goed of slecht is zonder een benchmark?
5. De klantenservice verbeteren
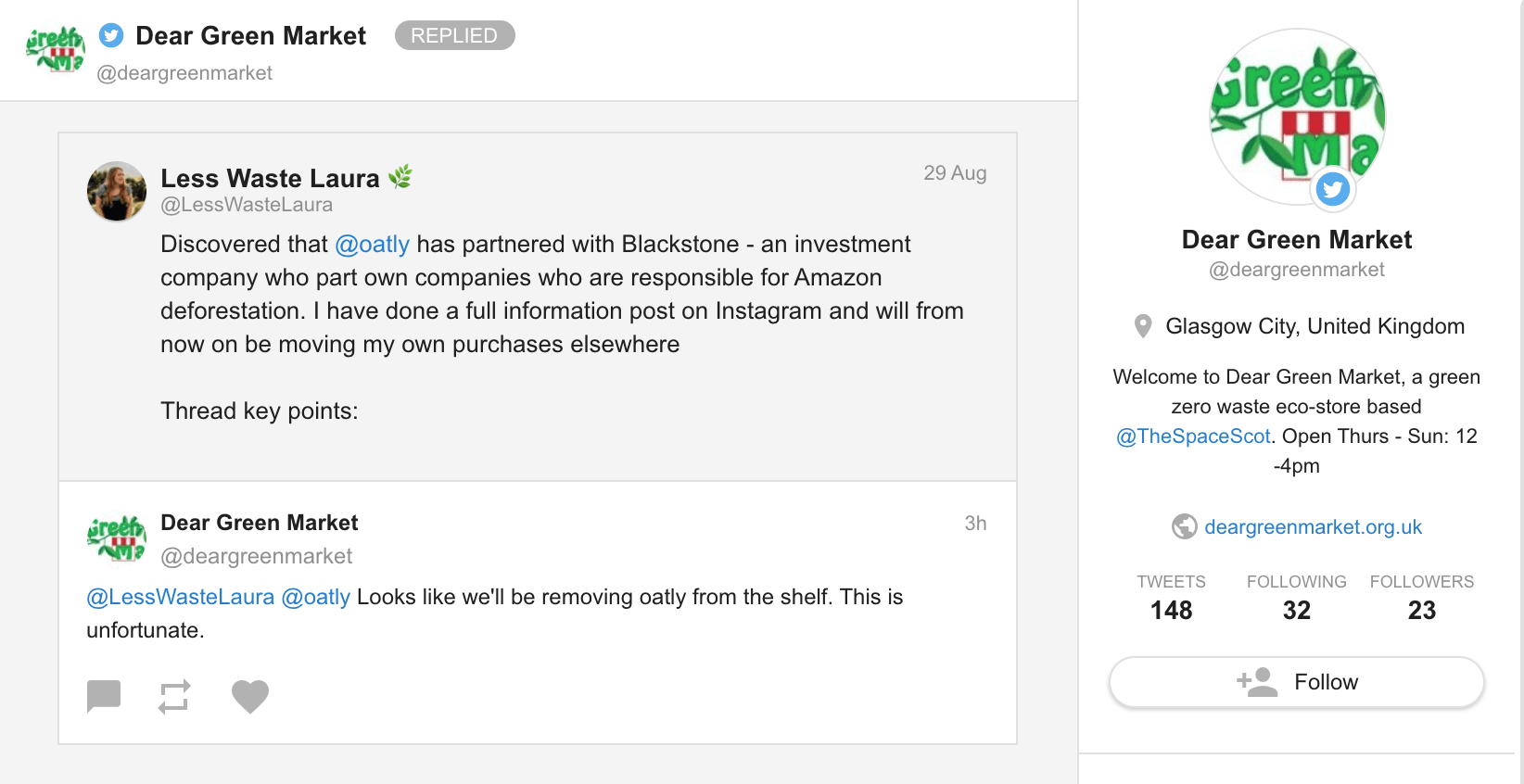
Het monitoren van de stemming onder klanten en begrijpen wat zij van uw producten of diensten vinden, kan uw klantenserviceteam ook helpen bij het stellen van prioriteiten.
Zorg ervoor dat je mentions die negatieve woorden over je merk bevatten (vooral die met een hoger bereik) als eerste aanpakt - in Awario kun je dat doen door filters te gebruiken in je mentions feed.
Als u deze negatieve gesprekken op sociale netwerken vroegtijdig opvangt, is de kans groot dat u de situatie voor deze specifieke klant kunt ombuigen en de klantervaring voor andere consumenten kunt verbeteren.
Door me aan te melden ga ik akkoord met de gebruiksvoorwaarden en het privacybeleid.
Hoe werkt sentimentanalyse?
In data science lingo is sentimentanalyse een classificatieprobleem: het algoritme krijgt stukken tekst voorgelegd die moeten worden geclassificeerd als positief, negatief of neutraal. Het probleem wordt gewoonlijk aangepakt met behulp van Natural Language Processing (NLP) op een van deze drie manieren: machine learning onder toezicht, regelgebaseerde technieken, of een combinatie van beide benaderingen.
Laten we eens kijken naar elk van deze modellen voor sentimentanalyse.
1. Bewaakt machinaal leren (ML)
Bij machine learning onder toezicht krijgt het systeem voor de training een volledige set gelabelde gegevens voorgelegd. Deze dataset bestaat uit documenten waarvan het sentiment al door menselijke beoordelaars (data scientists) is bepaald. De computer leert vervolgens de classificeerders voor sentimentanalyse van het document uit de trainingsset en labelt nieuwe invoergegevens (de testset).
Met andere woorden, door ML te gebruiken kunt u functies op laag niveau voor tekstanalyse, waar sentimentanalyse op steunt, automatiseren.
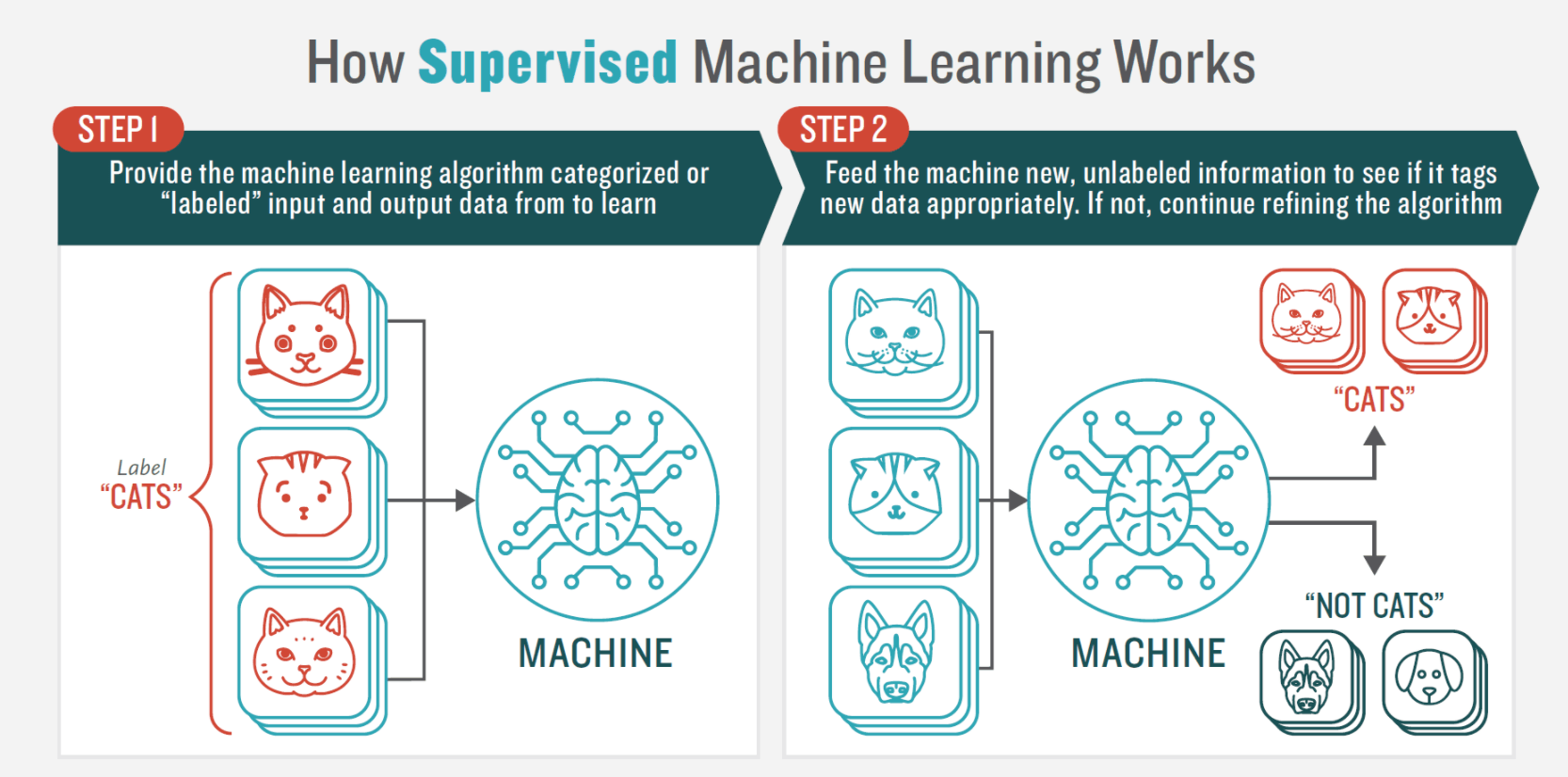
Bij dit model voor sentimentanalyse kunnen verschillende classificatiealgoritmen en neurale netwerken worden gebruikt, zoals Naive Bayes, logistische regressie, Support Vector Machines en andere.
Ongeacht de aanpak zal het systeem gewoonlijk een score toekennen aan alle onderwerpen, categorieën, woorden en zinnen in de tekst die het analyseert om het sentiment weer te geven: bijvoorbeeld op een schaal van -1 voor 'extreem negatief' tot 1 voor 'extreem positief'. Deze scores worden dan opgeteld voor alle woorden in de tekst en gedeeld door het aantal woorden in de tekst om de gemiddelde score te krijgen.
Vervolgens is het aan de onderzoeker om de specifieke grenzen vast te stellen. U zou bijvoorbeeld kunnen zeggen dat een totaalscore tussen -1 en -0,33 betekent dat de uitspraak negatief is, -0,33 tot 0,33 voor neutraal, en 0,33 tot 1 voor positief.
Voordelen: Met gesuperviseerde technieken voor machinaal leren kunnen getrainde modellen worden gemaakt die zijn toegesneden op het specifieke doel van de gegevensanalyse.
Nadelen: Deze modellen zijn vaak slecht aanpasbaar tussen domeinen of verschillende schrijfstijlen.
2. Op regels gebaseerde methoden
Een op regels gebaseerd systeem gebruikt een reeks door mensen opgestelde (en eventueel door machines verrijkte) regels voor tekstanalyse. Deze regels omvatten gewoonlijk sentimentlexicons (d.w.z. woordenboeken van vooraf gelabelde woorden en uitdrukkingen).
Hier is een heel eenvoudig voorbeeld van hoe een woordenboek eruit kan zien:
| Woord | Sentiment score |
|---|---|
| Fantastisch | 1 |
| Goed | 0.5 |
| Oké | 0 |
| Slecht | -0.5 |
| Verschrikkelijk | -1 |
Zodra het systeem aan het werk is, is de eerste stap het zoeken naar woorden uit het woordenboek in de tekst die het analyseert(entity extraction).
Vanaf daar is de wiskunde dezelfde als bij modellen voor machinaal leren: tel de scores voor elk woord op en deel het resultaat door het aantal woorden om het gemiddelde te krijgen.
Ten slotte bepaalt u het sentiment van de tekst op basis van de grenzen die u stelt aan positief, negatief en neutraal.
Laten we de volgende zin als voorbeeld nemen:
De koffie was oké, maar het eten was verschrikkelijk.
Aangezien deze tekst twee woorden uit ons woordenboek bevat, zou de score zijn:
(0 + (-1)) / 2 = -1 / 2 = -0.5
Als je besloten hebt dat een score tussen -1 en -0,33 betekent dat de uitspraak negatief is, dan heb je het - deze zin wordt door het systeem als negatief bestempeld.
Voordelen: Het bouwen van regelgebaseerde systemen is gemakkelijker dan het toepassen van ML-technieken, en zij vergen vaak minder middelen dan machine-learning algoritmen. Ze geven de onderzoeker ook volledige controle over de woordenschat en kunnen daarom een betere termdekking hebben.
Nadelen: Basisregelsystemen kijken naar individuele woorden of zinnen en niet naar hoe ze in een reeks worden gebruikt. Het toevoegen van nieuwe regels kan helpen, maar uiteindelijk kan het hele systeem erg complex worden. Bovendien is het aantal woorden in woordenboeken eindig, wat problemen kan opleveren voor natuurlijke taalverwerking in dynamische omgevingen (ik kijk naar jou, sociale media). Met andere woorden, de op een lexicon gebaseerde technologie zal vaak een voortdurende fine-tuning vereisen.
3. Hybride benaderingen
Soms combineren softwareontwikkelaars gecontroleerde machine learning en op lexicon gebaseerde benaderingen om de nauwkeurigheid van het sentiment te verbeteren zonder de prestaties op te offeren.
De technieken kunnen op verschillende manieren naast elkaar worden gebruikt, maar meestal zal een op regels gebaseerd systeem (dat doorgaans sneller is dan ML-algoritmen) proberen het sentiment van een uitspraak te classificeren. Indien een bepaalde mate van vertrouwen niet wordt bereikt (bv. wanneer weinig of geen woorden uit de zin beschikbaar zijn in het lexicon), zal een classificator voor machinaal leren worden gebruikt om het sentiment van de uitspraak te bepalen.
Voordelen: Hybride benaderingen kunnen de voordelen hebben van zowel regelgebaseerde als machine learning methoden, waardoor bedrijven die dit soort sentiment analyse gebruiken betere marketing inzichten krijgen. Ze kunnen meestal de perfomance voordelen hebben van lexicongebaseerde technieken, maar overtreffen deze in nauwkeurigheid om rekening te houden met uitspraken waarvan het sentiment niet gemakkelijk kan worden geïdentificeerd met een regelgebaseerde aanpak.
Nadelen: Natuurlijk kost het bouwen van deze systemen de meeste tijd en moeite.
4. Ondersteuning voor elke taal
Je leest het goed - het sentiment algoritme werkt voor elke taal! We hebben uitgebreide tests gedaan voor de talen die het populairst zijn bij Awario-gebruikers (Engels, Frans, Spaans, Duits en Portugees) en kleinere tests voor andere talen, en we zijn blij te kunnen zeggen dat de nauwkeurigheid van de sentimentanalyse voor geen enkele taal onder de 65% valt.
Hoe nauwkeurig is sentimentanalyse?
De nauwkeurigheid van sentimentanalyse is een term die wordt gebruikt om aan te geven hoeveel van de output van een sentimentanalysesysteem overeenkomt met menselijke evaluaties.
Het is echter niet zo eenvoudig als het lijkt - uit onderzoek blijkt dat menselijke beoordelaars het slechts in 65% tot 80% van de gevallen met elkaar eens zijn.
Om de verklaring te volgen, kun je dit parafraseren om te zeggen:
De nauwkeurigheid van de sentimentanalyse van het menselijk brein ligt tussen 65% en 80%.
Sentiment is vaak subjectief, waardoor de nauwkeurigheid moeilijk te meten is. Gemiddeld zijn onderzoekers het erover eens dat een systeem voor sentimentanalyse minstens 50% nauwkeurig moet zijn om als effectief te worden beschouwd; een nauwkeurigheid van meer dan 65% wordt als goed beschouwd, ook al klinkt dat misschien niet indrukwekkend.
Awario, met zijn sentimentanalyse nauwkeurigheid van iets meer dan 70%, doet het bijna net zo goed als mensen.
Er is nog een andere reden waarom nauwkeurigheid niet altijd de ultieme manier is om te meten hoe goed een algoritme is.
Hier is een mooi voorbeeld van wanneer dat niet zo is (niet gerelateerd aan sentimentanalyse):
Zou u iemand geloven die beweert een model te hebben bedacht waarmee hij terroristen die aan boord van een vlucht willen gaan met meer dan 99% nauwkeurigheid kan identificeren? Nou, hier is het model: gewoon elke persoon die vanaf een Amerikaanse luchthaven vliegt bestempelen als geen terrorist. Gezien de 800 miljoen gemiddelde passagiers op Amerikaanse vluchten per jaar en de 19 (bevestigde) terroristen die in de periode 2000-2017 aan boord van Amerikaanse vluchten zijn gegaan, bereikt dit model een verbazingwekkende nauwkeurigheid van 99,9999999%! Dat klinkt indrukwekkend, maar ik vermoed dat het Amerikaanse ministerie van Binnenlandse Veiligheid niet snel zal bellen om dit model te kopen. Hoewel deze oplossing een bijna perfecte nauwkeurigheid heeft, is dit een probleem waarbij nauwkeurigheid duidelijk geen adequate metriek is!
De twee andere factoren die de onderzoekers vertellen hoe goed hun algoritme is, zijn precisie en recall.
Precisie is het percentage door het systeem correct als X geïdentificeerde gevallen onder alle door het systeem als X geïdentificeerde gevallen.
Recall daarentegen isde verhouding tussen het aantal door het systeem correct geïdentificeerde gevallen van X en alle gevallen van X in de dataset.
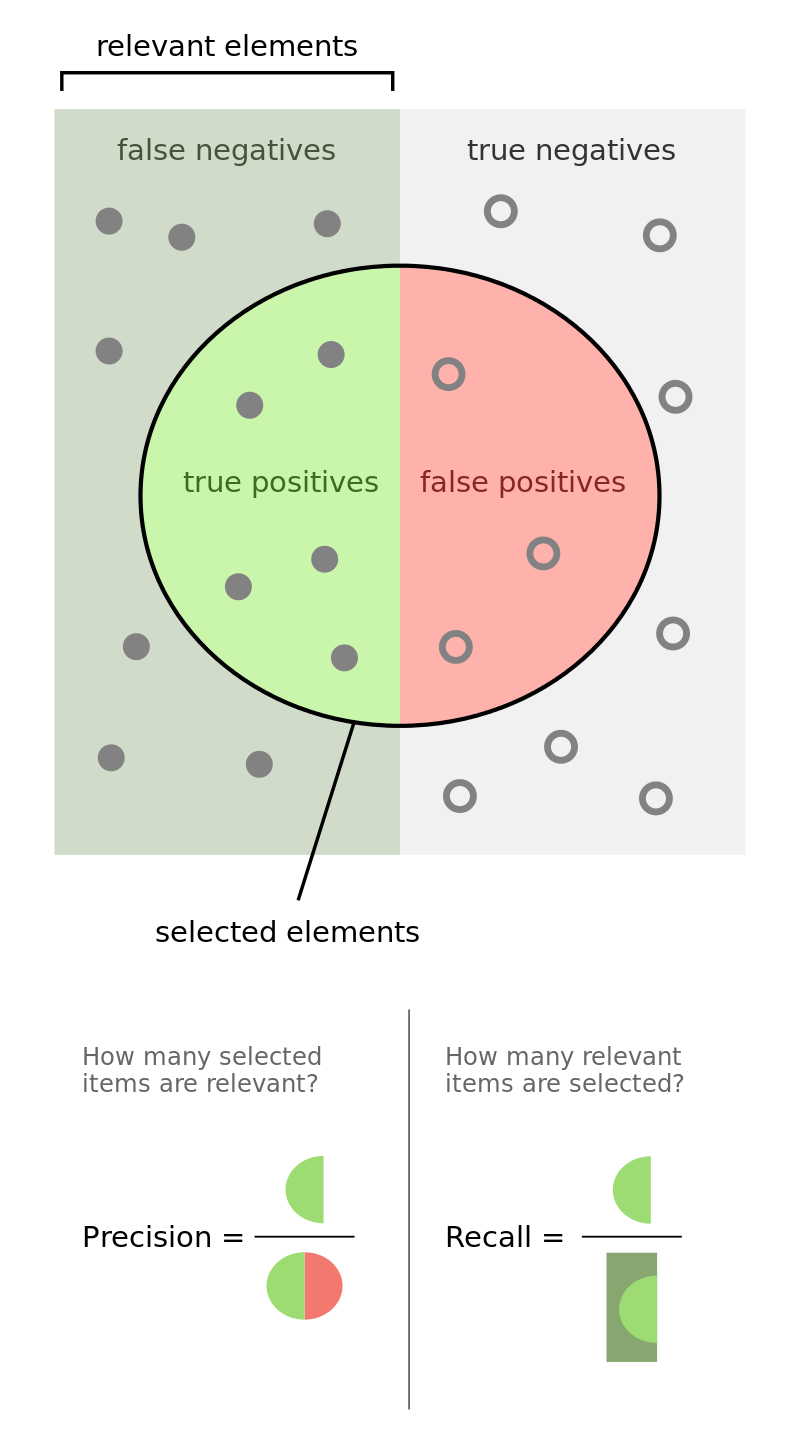
Stel bijvoorbeeld dat we een dataset van 10 uitspraken hebben: 7 daarvan worden door menselijke deskundigen als positief bestempeld, en 3 als negatief.
Een systeem voor sentimentanalyse identificeert 5 uitspraken als positief. Van deze 5 uitspraken zijn er slechts 3 daadwerkelijk positief (zoals beoordeeld door menselijke deskundigen).
De precisie van het systeem is 3/5 en de recall is 3/7.
Wat zijn de beperkingen van sentimentanalyse?
We hebben gezien dat sentimentanalyse zelfs voor mensen lastig is, laat staan voor machines - maar waarom? Dit zijn de grootste uitdagingen voor sentimentanalysesystemen (dit geldt voor alle talen).
1. Sarcasme

Elke vorm van natuurlijke taalverwerking is lastig voor korte documenten, en sentimentanalyse vormt daarop geen uitzondering. Berichten op sociale media zijn over het algemeen korter dan andere soorten webinhoud, zoals nieuwsartikelen, wat betekent dat er vaak weinig context is om mee te werken. Dit is vooral belangrijk voor sarcastische of ironische uitspraken.
In veel gevallen is sarcasme vrij duidelijk voor mensen, maar uiterst moeilijk te detecteren voor machines.
Hier is een voorbeeld:
Het kostte me maar 5 minuten om een koffie te halen bij Starbucks. Geweldig begin van de dag!
Het kostte me maar 30 minuten om een koffie te halen bij Starbucks. Geweldig begin van de dag!
2. Negaties
Negaties zijn een taalkundig middel om de betekenis van woorden, zinnen en zelfs hele zinnen om te keren. Voor sentimentanalyse is het niet alleen belangrijk om negaties te identificeren, maar ook om uit te zoeken welke woorden erdoor worden beïnvloed, zodat het systeem hun sentiment kan omkeren.
Net als sarcasme is negatie voor mensen vrij gemakkelijk te interpreteren, maar voor computers kan het een hele uitdaging zijn.
Ik zou niet zeggen dat de koffie bijzonder goed was.
Om met negatie om te gaan, zullen algoritmen voor sentimentclassificatie vaak het sentiment van alle woorden vanaf het negatiewoord tot aan het volgende leesteken terugdraaien. Deze aanpak kan echter soms mislukken, zoals u kunt zien in het onderstaande voorbeeld.
Ik hoopte dat de koffie geweldig zou zijn. Dat was niet zo.
3. Ambiguïteit
Emotionele woorden, zoals liefde en haat, zijn gemakkelijk te interpreteren voor zowel mensen als machines. Sommige woorden kunnen echter in de ene context negatief zijn, en in een andere neutraal of positief, zoals in het onderstaande voorbeeld.
Ik drink ijskoude koffie in de zomer.
Toen ik eindelijk mijn koffie kreeg, was hij ijskoud.
4. Multipolariteit
Vaak drukt de tekst die je analyseert meerdere emoties tegelijk uit. Wanneer je een tekst te zien krijgt die één emotie uitdrukt ten aanzien van een bepaald object of onderwerp, en een andere emotie ten aanzien van een ander, heb je te maken met multipolariteit.
Starbucks koffie is veel beter dan Dunkin'.
(Schaamteloze plug: als je je afvraagt welke echt beter is, ga dan naar onze social listening analyse van de twee merken).
In dit geval zou een basis opinion mining systeem kunnen concluderen dat het sentiment van de uitspraak positief is. Maar als het merk dat je volgt Dunkin' is, ben je het daar vast niet mee eens. Om met multipolariteit om te gaan, wordt een benadering gebruikt die aspect-gebaseerde sentimentanalyse heet.
Heb je conclusies getrokken uit wat je gelezen hebt?
Ik hoop dat deze gids direct inzicht heeft gegeven in sentimentanalyse, het gebruik en de uitdagingen ervan. Voor een kort moment zou je kunnen denken dat het moeilijk te gebruiken is of dat het helemaal geen nut heeft voor marketeers. Afhankelijk van uw doelstellingen kunt u sentimentanalyse echter gemakkelijk aanpassen aan uw dagelijkse marketingroutine.
Heb je nog vragen over sentiment? Laat het ons weten! Ga naar onze sociale pagina's om je commentaar achter te laten en daar je vragen te stellen.


