センチメント分析へのガイド。センチメント分析とは何か、どのように機能するのか?


記事の要約
多くの専門家は、ネガティブなセンチメントはウェブ上でのあなたのブランドのビジネス上の評判に悪影響を与えると警告しています。このガイドを読んで、センチメント分析とは何か、どのように機能するかを理解し、使用すべきかどうかを判断してください。
20分読了
センチメント分析は、究極のバズワードです。そして、このバズワードは非常に誤解されやすい概念でもあります。
アワリオでは、ブランドセンチメント分析システムを提供していますが、リリースしてからセンチメントに関する質問を多く受けるようになりました。
このガイドは、センチメント分析の使用方法から、その背後にあるメカニズムやNLP技術の裏側まで、センチメント分析についてより深く理解するのに役立つことでしょう。
まずは質問のゾウから。
センチメント分析とは?
センチメント分析とは、オピニオンマイニングとも呼ばれ、あるトピックや現象に対して誰かが表現した感情(ポジティブ感情、ネガティブ感情、ニュートラル感情に分類されることが多い)を判断するプロセスである。
ソーシャルリスニングと オンラインレピュテーションマネジメントの文脈では、センチメントの分析は、顧客の声を捉え、ブランド、企業、製品、または個人に対する消費者の態度を判断するために最も一般的に使用されています。
センチメント分析はどのように使われているのですか?
センチメント分析は、ソーシャルリスニングツールに求めるべき最も重要なものであると言っても過言ではありません。ブランドの健全性の分析から顧客サービスの改善まで、センチメント分析ツールでできる主なことをいくつかご紹介します。
1.ブランドの健全性の監視
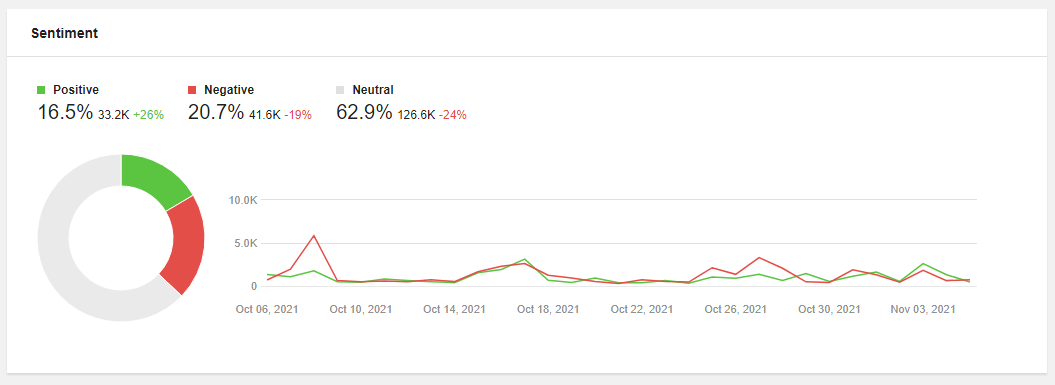
センチメント分析は、ブランドをモニタリングし、ブランドの健全性を評価するための重要な要素です。ソーシャルメディアモニタリングのダッシュボードで、ブランドについての会話におけるポジティブとネガティブの比率に注目し、ポジティブとネガティブの両方のフィードバックにおける主要なテーマを調べて、顧客が何を最も賞賛し、何に不満を持つ傾向があるかを学びましょう。

2.レピュテーションクライシスを早期に察知する
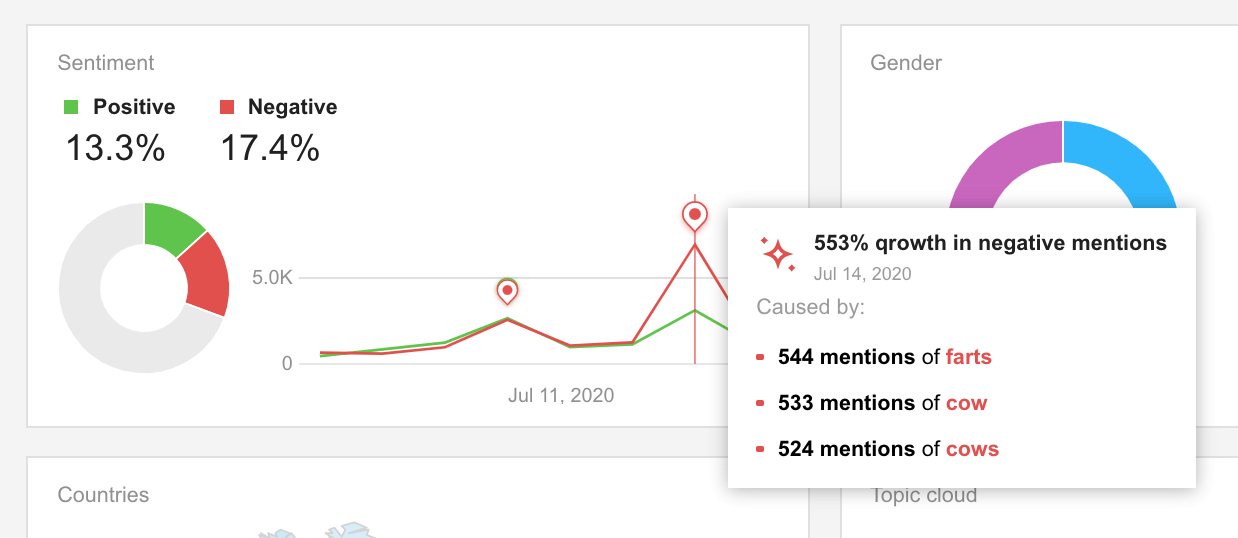
センチメント分析は、ソーシャルメディア分析やレポーティングにのみ使用されるわけではありません。ソーシャルリスニングダッシュボードに毎日ログインし、ネガティブな言及が急増していないかどうかを確認することも同様に重要です。
また、Awarioでは、インサイトを利用することで、ネガティブまたはポジティブな会話の量が急増した理由を理解することができます。 これらのインサイトをクリックすることで、過去とリアルタイムのデータを深く掘り下げ、ネガティブ(またはポジティブ)な言及の流入の原因を確認することが可能です。
徹底したセンチメント分析により、ウェブ上でネガティブな言及が驚くほど増加した場合、ブランドの評判を守ることができます。また、ポジティブとネガティブのパフォーマンスの根源を特定するのにも役立ちます。
3.キャンペーンのパフォーマンス追跡
自社ブランドのモニタリングと同じように、マーケティングキャンペーン、コラボレーション、イベントなど、文字通りオンラインで話題を呼ぶ企業のあらゆる取り組みに関する言及を追跡することができます。
ブランド・モニタリングと同様に、センチメント分析でキャンペーン全体のセンチメントを測定し、その背後にある理由を特定するためにスパイクを探すことができます。 早い話が、アワリオは多言語のセンチメント分析を提供しているので、世界中でキャンペーンがどのように機能しているかを追跡することができるのです。
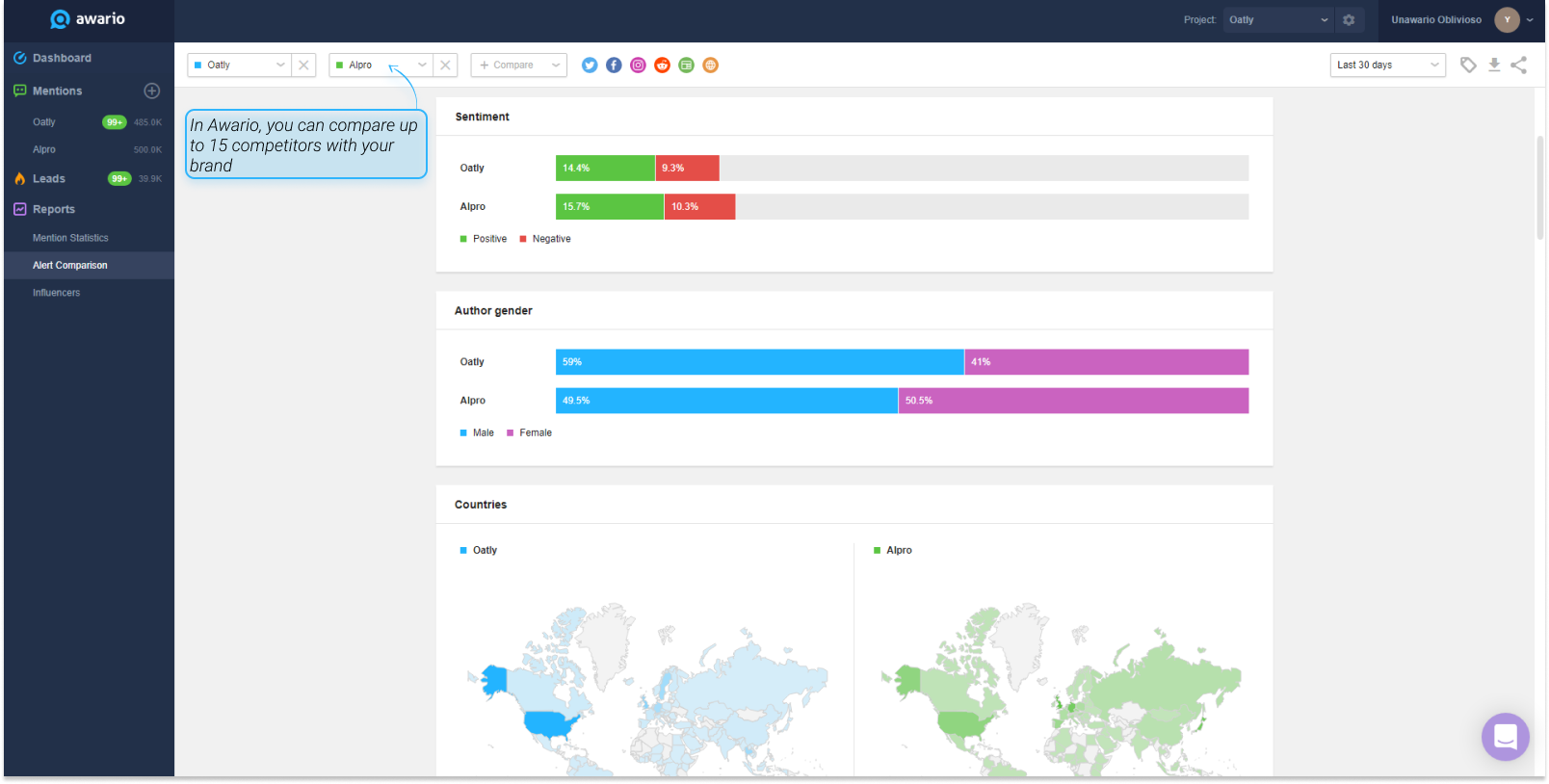
4.競合他社分析の実施
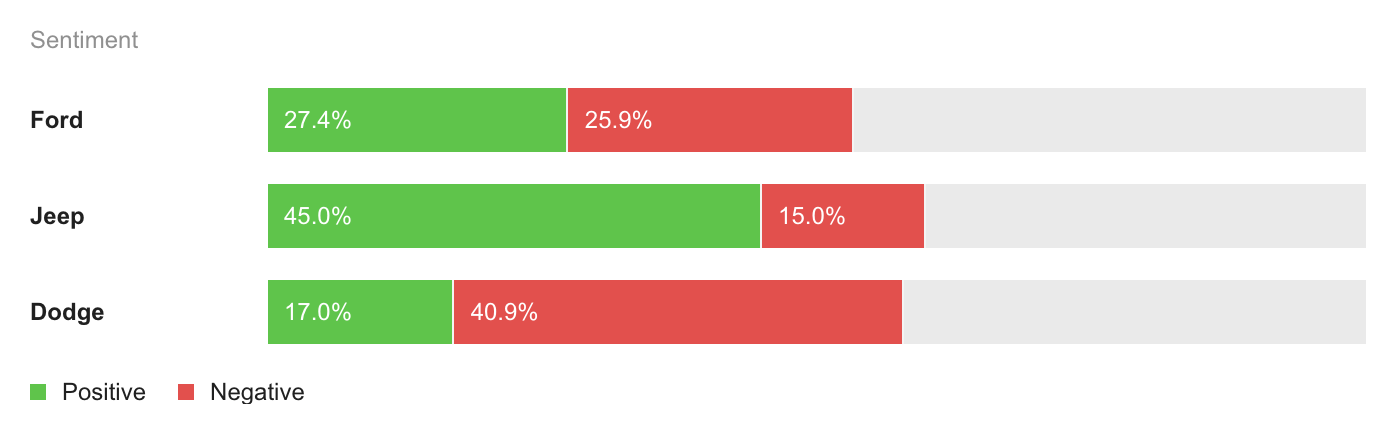
競合他社のセンチメントをモニタリングすることで、顧客が自社製品のどの部分に最も(そして最も)興奮しているかを確認することができます。さらに、競合他社のセンチメントは、自社ブランドや製品に関する言及の背後にあるセンチメントを分析する際のベンチマークとしても役立ちます。
例えば、言及の50%がポジティブで、40%がネガティブ、残りがニュートラルだとします。それが良いことなのか悪いことなのか、ベンチマークなしでどうやって判断するのでしょうか?
5.カスタマーケアの向上
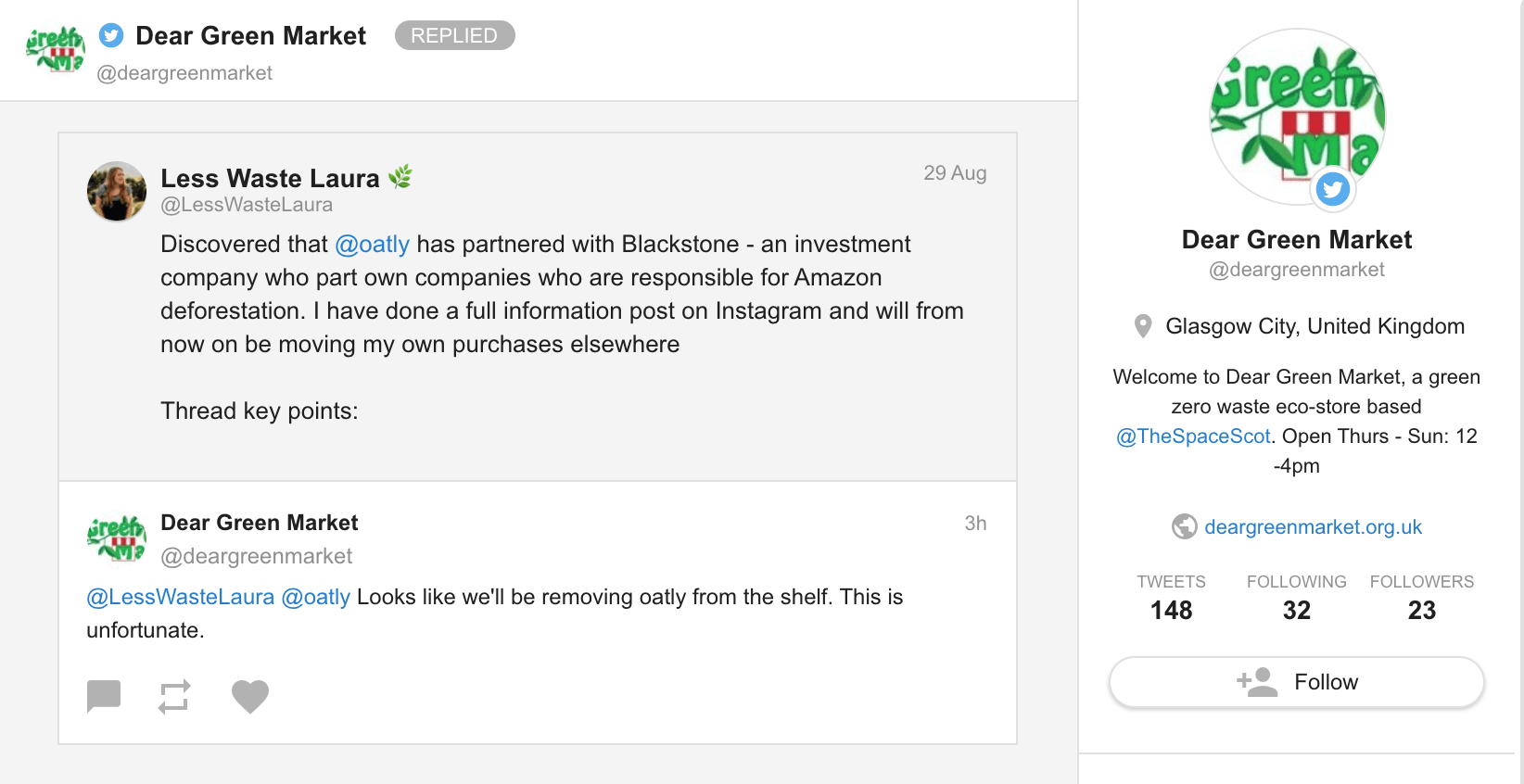
お客様の感情をモニターし、製品やサービスに対してどのように感じているかを理解することは、カスタマーサポートチームが仕事の優先順位を決める際にも役立ちます。
自社ブランドに関するネガティブな言葉を含むメンション(特にリーチ数の多いもの)には、必ず最初に対処しましょう。Awarioでは、メンションフィードでフィルターを使用することで対処することができます。
ソーシャルネットワーク上のネガティブな会話を早期にキャッチすれば、そのクライアントの状況を好転させ、他の消費者のカスタマーエクスペリエンスを向上させることができる可能性があるのです。
センチメント分析の仕組みは?
データサイエンス用語では、センチメント分析は分類問題であり、アルゴリズムには肯定、否定、中立に分類する必要のあるテキストの断片が提示されます。 この問題は通常、自然言語処理(NLP)の助けを借りて、教師あり機械学習、ルールベースの技術、または2つのアプローチの組み合わせの3つの方法のいずれかで取り組まれます。
では、それぞれのセンチメント分析モデルについて見ていきましょう。
1.教師あり機械学習(ML)
教師あり機械学習では、システムには学習のためにラベル付きデータのフルセットが提示される。このデータセットは、人間の評価者(データサイエンティスト)によってセンチメントが既に決定されている文書で構成される。その後、コンピュータは学習セットからドキュメントのセンチメント分析分類子を学習し、新しい入力データ(テストセット)のラベル付けを行う。
つまり、MLを利用することで、感情分析が依拠する低レベルのテキスト分析機能を自動化することができるのです。
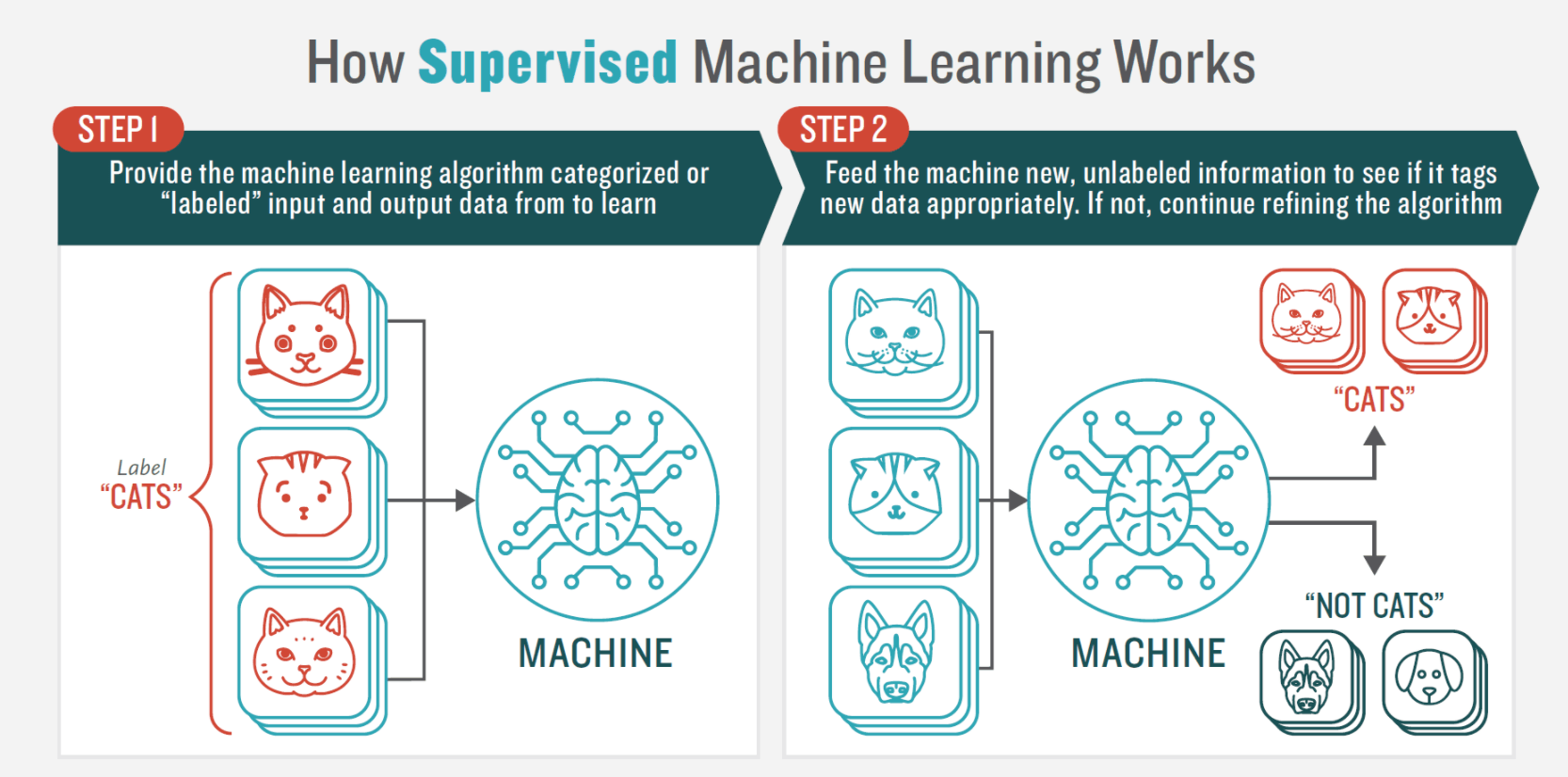
このセンチメント分析モデルでは、Naive Bayes、ロジスティック回帰、サポートベクターマシンなど、さまざまな分類アルゴリズムやニューラルネットワークを利用することが可能である。
どのようなアプローチであっても、システムは通常、分析対象のテキストに含まれるすべてのトピック、カテゴリ、単語、フレーズに、センチメントを反映するスコアを割り当てます。例えば、「極めて否定的」を表す-1から「極めて肯定的」を表す1までの尺度で評価します。これらのスコアは、テキスト内のすべての単語について合計し、単語数で割って平均スコアを得ます。
そこから、特定の境界線を設定することは、研究者次第です。例えば、総合スコアが-1~-0.33の場合はその発言が否定的であることを意味し、-0.33~0.33の場合は中立、0.33~1の場合は肯定的というように使用することができます。
長所:教師あり機械学習の技術は、データ分析の特定の目的に合わせて学習済みモデルを作成することができる。
短所:これらのモデルは、ドメイン間や異なるライティングスタイルへの適応性が低いことが多い。
2.ルールベース手法
ルールベースシステムは、テキスト分析に人間が作成した(オプションで機械的に強化した)ルールのセットを使用します。これらのルールには、一般的に感情辞書(事前にラベル付けされた単語や表現の辞書)が含まれます。
以下は、辞書のごく基本的な例です。
| ワード | センチメントスコア |
|---|---|
| ファンタスティック | 1 |
| 良い | 0.5 |
| オーケー | 0 |
| 悪い | -0.5 |
| ひどい | -1 |
システムが動き出すと、まず解析対象のテキストから辞書に載っている単語を探す(固有表現抽出)。
そこからの計算は、機械学習モデルと同じで、すべての単語のスコアを合計し、結果を単語数で割って平均値を求めます。
最後に、ポジティブ、ネガティブ、ニュートラルに設定した境界線に基づいて、テキストのセンチメントを決定します。
次の文章を例にとって考えてみましょう。
コーヒーはまあまあでしたが、食事は最悪でした。
この文章には、私たちの辞書にある単語が2つ含まれているので、スコアは次のようになります。
(0 + (-1)) / 2 = -1 / 2 = -0.5
スコアが-1から-0.33の間であれば、この文は否定的であると判断されます。
長所:ルールベースシステムの構築は、機械学習技術を導入するよりも簡単であり、機械学習アルゴリズムほどリソースを必要としない場合が多い。また、研究者が語彙を完全にコントロールできるため、より優れた用語カバー率を実現できる。
短所: 基本的なルールベースのシステムは、個々の単語やフレーズを見るのであって、それらが一連の流れの中でどのように使われているかを見るのではありません。新しいルールを追加することは有効かもしれないが、最終的にはシステム全体が非常に複雑になる可能性がある。その上、辞書に載っている単語の数は有限であるため、動的な環境(ソーシャルメディアなど)での自然言語処理に問題が生じる可能性がある。つまり、辞書ベースの技術では、継続的な微調整が必要になることが多いのです。
3.ハイブリッドアプローチ
ソフトウェア開発者は、教師あり機械学習と語彙ベースのアプローチを組み合わせて、パフォーマンスを犠牲にすることなくセンチメントの精度を向上させることがあります。
これらの技術はさまざまな方法で並行して使用できますが、最も一般的には、ルールベースのシステム(一般的にMLアルゴリズムより高速)が文のセンチメントを分類しようとします。 ある程度の信頼性が得られない場合(文の単語がほとんど、または全く語彙にない場合など)、機械学習分類器を使用して文のセンチメントを特定します。
長所 ハイブリッドアプローチは、ルールベースと機械学習の両方の利点を持ち、この種のセンチメント分析を使用する企業がより良いマーケティングインサイトを得るのに役立ちます。 レキシコンベースの手法とほぼ同等のパフォーマンスを持ちながら、ルールベースのアプローチではセンチメントを容易に特定できないステートメントを考慮し、それを上回る精度で分析することが可能です。
短所: 当然ながら、これらのシステムの構築には最も時間と労力がかかる。
4.各言語への対応
その通りです。センチメントアルゴリズムは、あらゆる言語で機能します。Awarioのユーザーに最も人気のある言語(英語、フランス語、スペイン語、ドイツ語、ポルトガル語)と、その他の言語について小規模なテストを行いましたが、センチメント分析の精度はどの言語も65%を下回りませんでした。
センチメント解析の精度は?
センチメント分析の精度は、センチメント分析システムの出力が人間の評価とどの程度一致するかを示す用語である。
しかし、人間の評価者は65%から 80%の確率でお互いの意見を一致させるという研究結果もあり、見た目ほど簡単ではありません。
この文言に従うと、こう言い換えることができます。
人間の脳による感情分析の精度は65%~80%です。
センチメントは主観的であることが多いため、精度を測定することは困難です。平均して、研究者はセンチメント分析システムが効果的であると見なされるには、少なくとも50%の精度が必要であることに同意しています。
感情分析の精度が70%強のAwarioは、ほぼ人間と同じような結果を出しています。
また、アルゴリズムの良し悪しを測るのに、必ずしも精度が究極の方法でない理由はもう一つあります。
そうでない場合の素晴らしい例を紹介します(センチメント分析とは関係ありません)。
99%以上の精度で飛行機に乗ろうとするテロリストを特定するモデルを完全に頭の中で作り上げたと主張する人物を信じますか?そのモデルとは、アメリカの空港から飛行機に乗るすべての人に、テロリストではないというラベルを貼るというものです。米国便の年間平均搭乗者数が8億人、2000年から2017年にかけて米国便に搭乗した19人の(確定)テロリストを考えると、このモデルは99.9999999%という驚異的な精度を達成することになります印象的に聞こえるかもしれませんが、米国国土安全保障省がこのモデルを購入するためにすぐに電話をかけてくることはないだろうと私は思っています。このソリューションはほぼ完璧な精度を持っていますが、この問題は、明らかに精度が適切な指標ではないものです
このほか、研究者のアルゴリズムの優秀さを示すものとして、精度と想起率の2つがある。
精度とは、システムによってXと識別されたすべてのインスタンスのうち、システムによってXと正しく識別されたインスタンスの割合である。
一方、Recallは 、 データセット中のXの全インスタンスに対する、システムが正しく認識したXの インスタンスの数の比率である 。
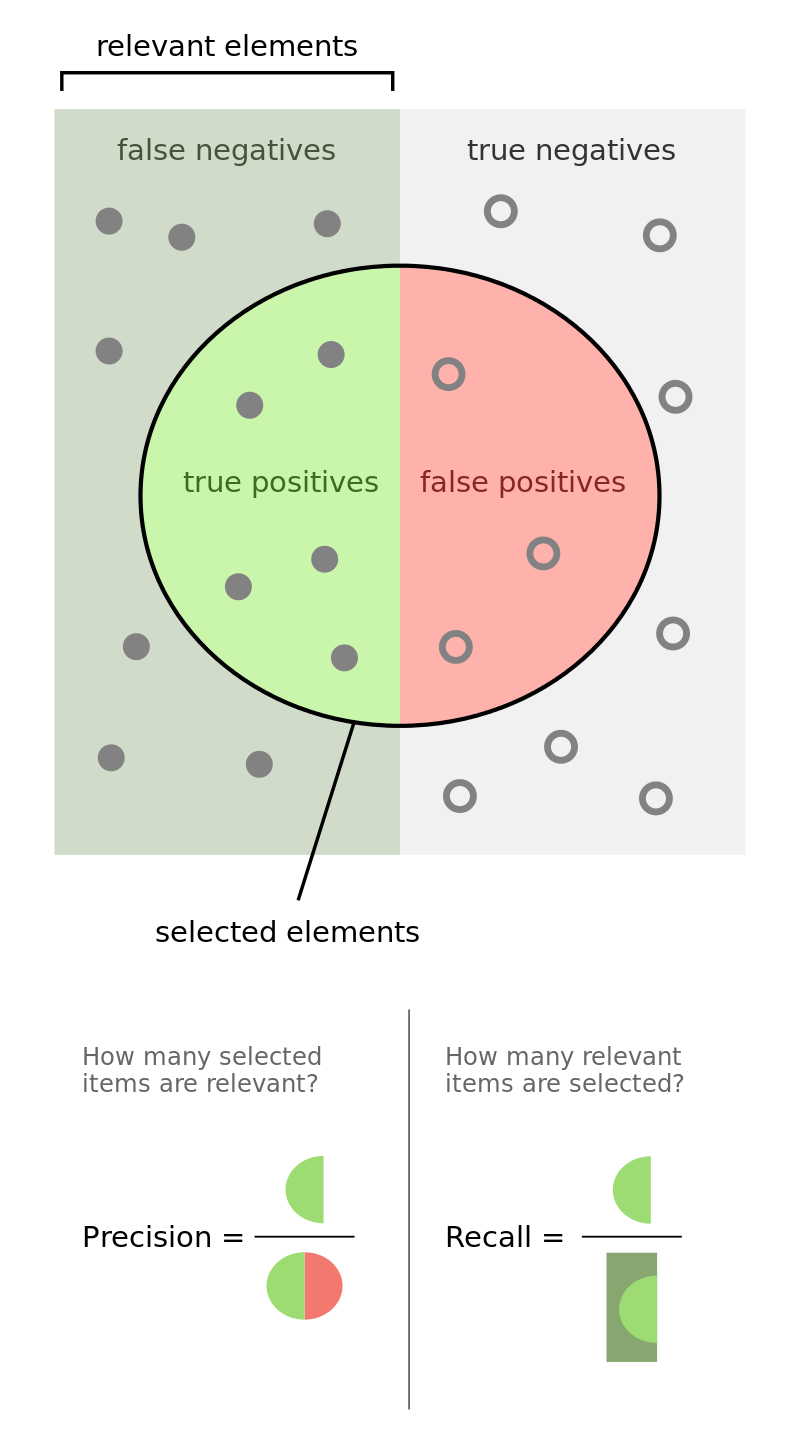
例えば、10個の発言からなるデータセットがあるとする。そのうち7個は人間の専門家がポジティブとラベル付けし、3個はネガティブとラベル付けした。
感情分析システムは、5つのステートメントを肯定的であると判断します。これらの5つのインスタンスのうち、3つだけが実際に肯定的である(人間の専門家によって評価される)。
システムの精度は3/5で、再現性は3/7である。
センチメント分析の注意点とは?
感情分析は、機械はもちろんのこと、人間にとっても厄介なものであることを見てきました。ここでは、センチメント分析システムが直面する最大の課題を紹介します(これはすべての言語に当てはまります)。
1.皮肉

どのような自然言語処理でも、短い文書は扱いにくいものですが、センチメント分析も例外ではありません。ソーシャルメディアの投稿は、一般的にニュース記事などの他の種類のウェブコンテンツよりも短いため、扱うべき文脈がほとんどないことがよくあります。これは、皮肉や皮肉を込めた発言には特に重要です。
多くの場合、皮肉は人間には一目瞭然ですが、機械にとっては非常に厄介なものです。
以下はその一例です。
スターバックスでコーヒーを飲むのに5分しかかからなかった。一日の始まりは最高です
スターバックスでコーヒーを飲むのに30分しかかからなかった。一日の始まりは最高です
2.ネガティヴ
否定は、単語、フレーズ、さらには文全体の意味を反転させる言語学的な手段である。感情分析のためには、否定を識別するだけでなく、どの単語がその影響を受けているかを把握し、システムが感情を元に戻すことができるようにすることが重要である。
皮肉と同じように、否定は人間にとってかなり解釈しやすいものですが、コンピュータにとってはかなり難しいものです。
コーヒーが特に美味しかったとは言いません。
否定を処理するために、センチメント分類アルゴリズムでは、否定の単語で始まり、次の句読点までのすべての単語のセンチメントを元に戻すことがよくあります。しかし、このアプローチは、以下の例に見られるように、時には失敗することがあります。
コーヒーが美味しいと期待していたのですがそうでもなかった。
3.アンビギュイティ
愛や 憎しみといった感情的な言葉は、人間にも機械にも解釈しやすいものです。しかし、以下の例のように、ある文脈では否定的で、別の文脈では中立または肯定的になる言葉もあります。
夏場はアイスコーヒーを飲むことが多いですね。
ようやく手に入れたコーヒーは、氷のように冷たくなっていた。
4.多極化
分析対象のテキストが、一度に複数の感情を表現していることはよくあることです。ある対象やトピックに対してある感情を表し、別の対象に対しては別の感情を表すテキストが提示された場合、それは多極化を扱っていることになります。
スターバックスのコーヒーは、ダンキンよりずっと美味しいです。
(恥ずかしながら、この2つのブランドについて、ソーシャルリスニングによる分析をご覧ください。)
この場合、基本的なオピニオン・マイニング・システムは、このフレーズから、この文のセンチメントはポジティブであると結論付けるかもしれません。しかし、あなたがモニターしているブランドがDunkin'であれば、きっと同意しないでしょう。多極化に対処するために、アスペクトベースのセンチメント分析と呼ばれるアプローチが使用されます。
読んだ内容から何か結論が出たのでしょうか?
このガイドでは、センチメント分析について、その用途や課題について直接的な洞察を得ることができたと思います。一瞬、「使いにくい」「マーケターには全く役に立たない」と思われたかもしれません。しかし、目的によっては、センチメント分析を日々のマーケティングルーチンに簡単に適応させることができます。
センチメントについてまだ質問がありますか?ぜひお聞かせください。私たちのソーシャルページにコメントを残し、そこで質問をしてください。


