A guide to sentiment analysis: What is it and how does it work?


Article summary
Many pros caution you that negative sentiment harms your brand’s business reputation on the web. Read this guide to understand what it really is, how sentiment analysis works, and decide whether you should use it.
20 minutes read
Sentiment analysis is the ultimate buzzword. And as buzzwords go, it's a concept that's very often misunderstood.
At Awario, we provide a brand sentiment analysis system, and we've been getting a lot of questions about sentiment since we released it.
With any luck, this guide will help you understand more about sentiment analysis: from how it's used to the ins and outs of the mechanics and NLP techniques behind it.
Let's start with the elephant of a question:
What is sentiment analysis?
Sentiment analysis, also called opinion mining, is the process of determining the emotion (often classified as positive sentiment, negative, or neutral) expressed by someone towards a topic or phenomenon.
In the context of social listening and online reputation management, analyzing sentiment is most commonly used to capture the voice of the customer and determine the attitude of consumers towards a brand, company, product, or person.
How is sentiment analysis used?
Sentiment analysis is arguably the most important thing to look for in a social listening tool. From analyzing brand health to improving customer service, here are some of the main things sentiment analysis tools help you do.
1. Monitor brand health
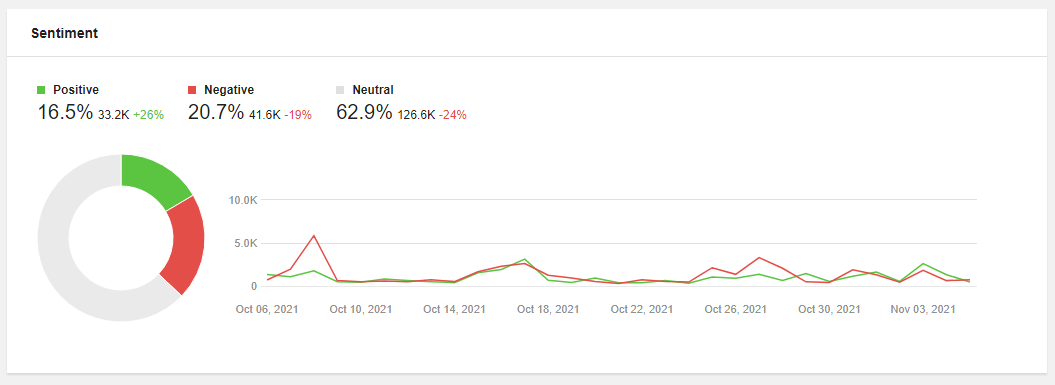
Sentiment analysis is an important part of monitoring your brand and assessing brand health. In your social media monitoring dashboard, keep an eye on the ratio of positive and negative mentions within the conversations about your brand and look into the key themes within both positive and negative feedback to learn what your customers tend to praise and complain about the most.

2. Spot reputation crises early
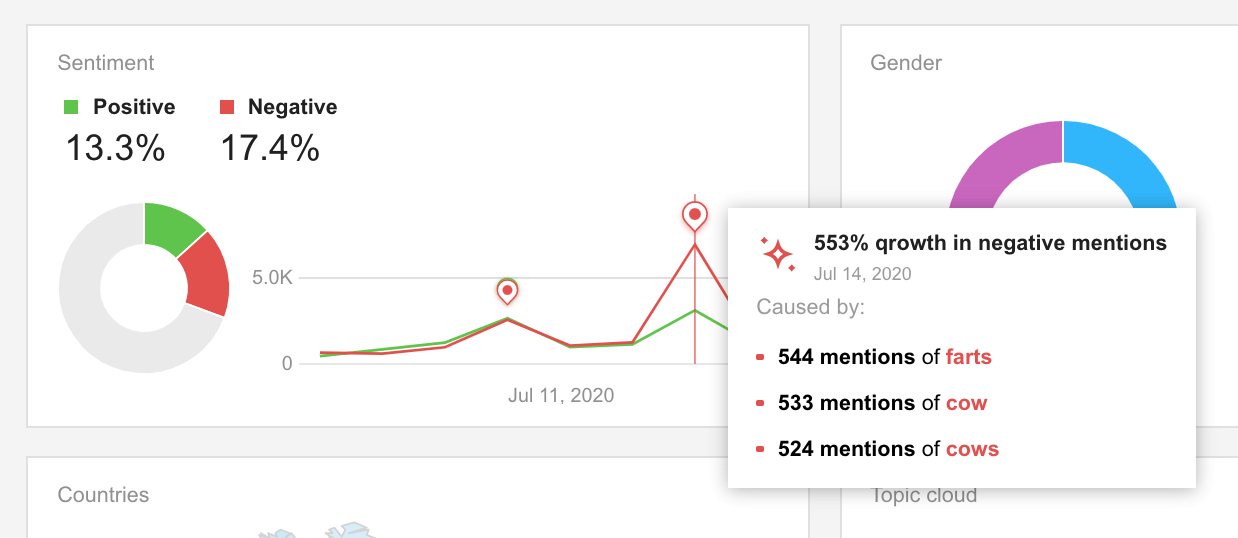
Sentiment analysis isn't only used for social media analytics and reporting. It's just as important to log into your social listening dashboard daily and look out for any spikes in negative mentions — this way, you'll be able to catch a reputation crisis early and prevent it from turning into a full-on disaster.
In Awario, with the help of Insights, you can also understand the reasons behind any spikes in the volume of negative or positive conversations. By clicking on these insights, you can dig deeper into historical and real-time data and see what caused the influx of negative (or positive) mentions.
Thorough sentiment analysis can save your brand reputation when its negative mentions increase on the web at an alarming rate. Also, it helps you identify the roots of positive and negative performance.
By signing up I agree to the Terms of Use and Privacy Policy
3. Track performance of campaigns
In the same way you're monitoring your brand, you can track mentions of your marketing campaigns, collaborations, events you're organizing, or literally any other initiative by your company that generates buzz online.
Just like with brand monitoring, you can use sentiment analysis to measure the overall sentiment around the campaign and look out for spikes to identify the reasons behind them. As a quick point, Awario provides multilingual sentiment analysis, so you can track how your campaign works over the world.
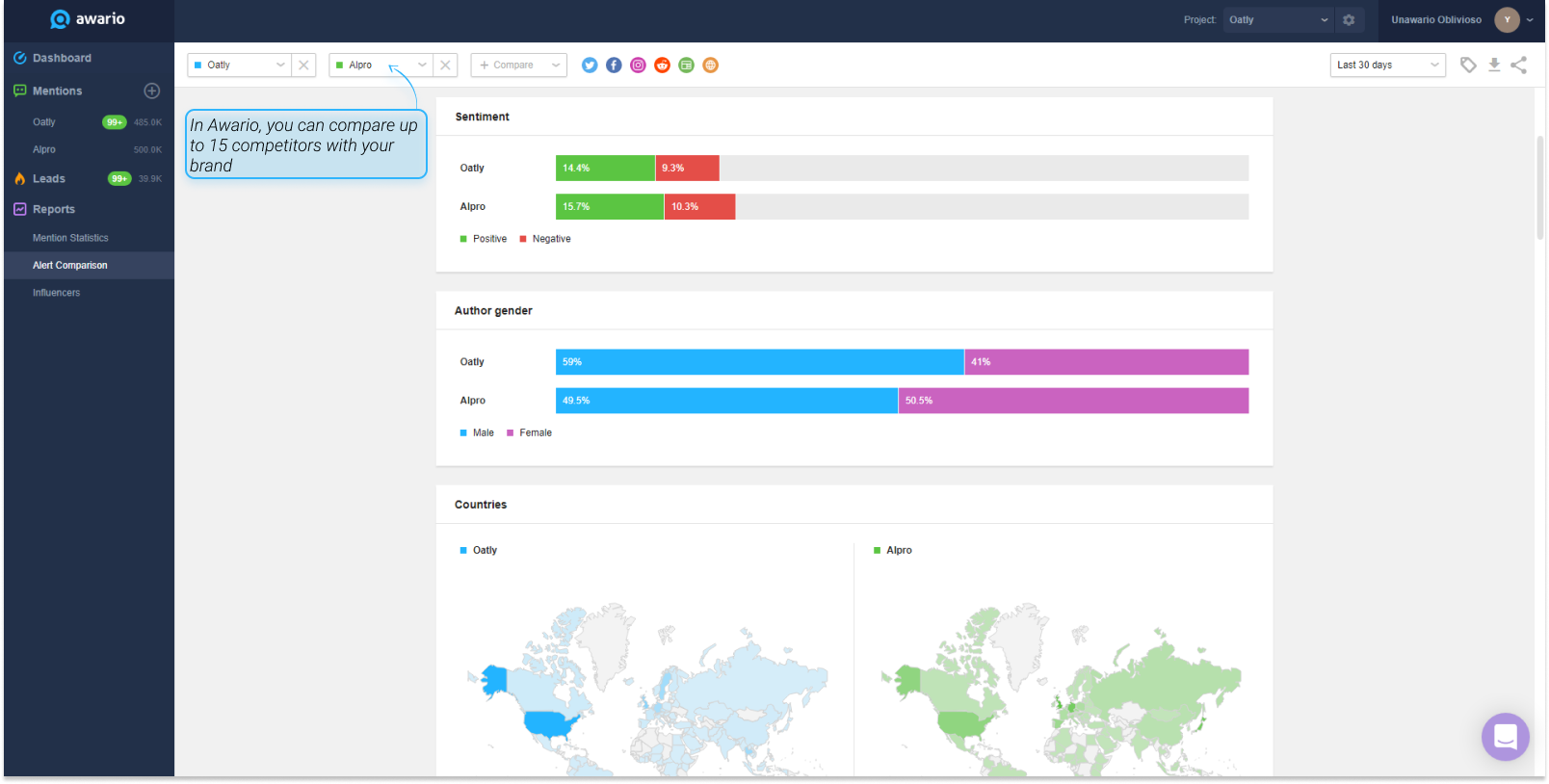
4. Perform competitor analysis
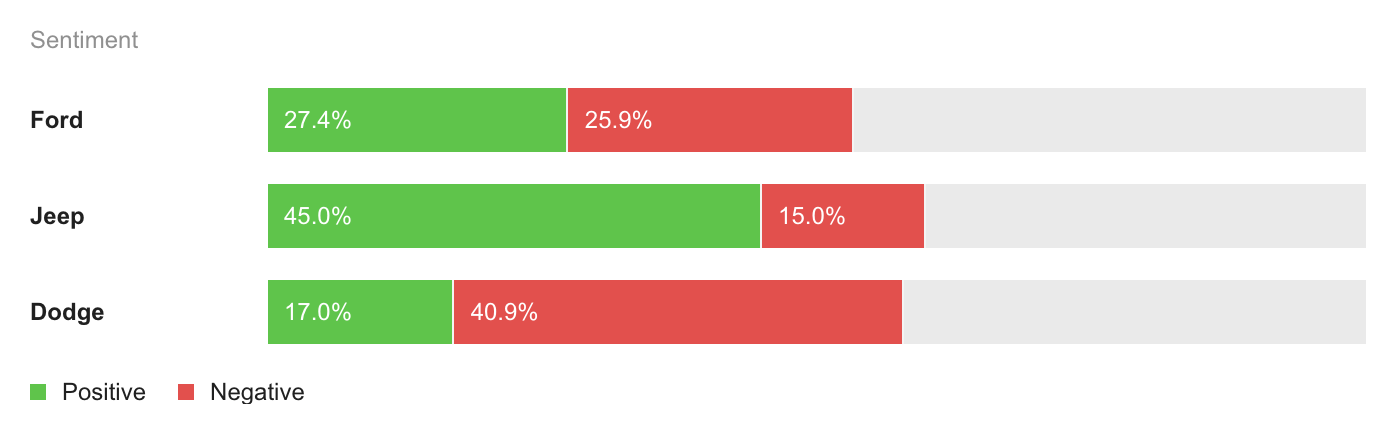
Monitoring your competitors' sentiment will help you see which aspects of their products customers are most (and least) excited about. On top of that, competitor sentiment can also serve as a benchmark when you analyze the sentiment behind the mentions of your own brand and product.
Let’s say, 50% of your mentions are positive, 40% are negative, and the rest are neutral. How do you know if that’s a good thing or a bad thing without a benchmark?
5. Improve customer care
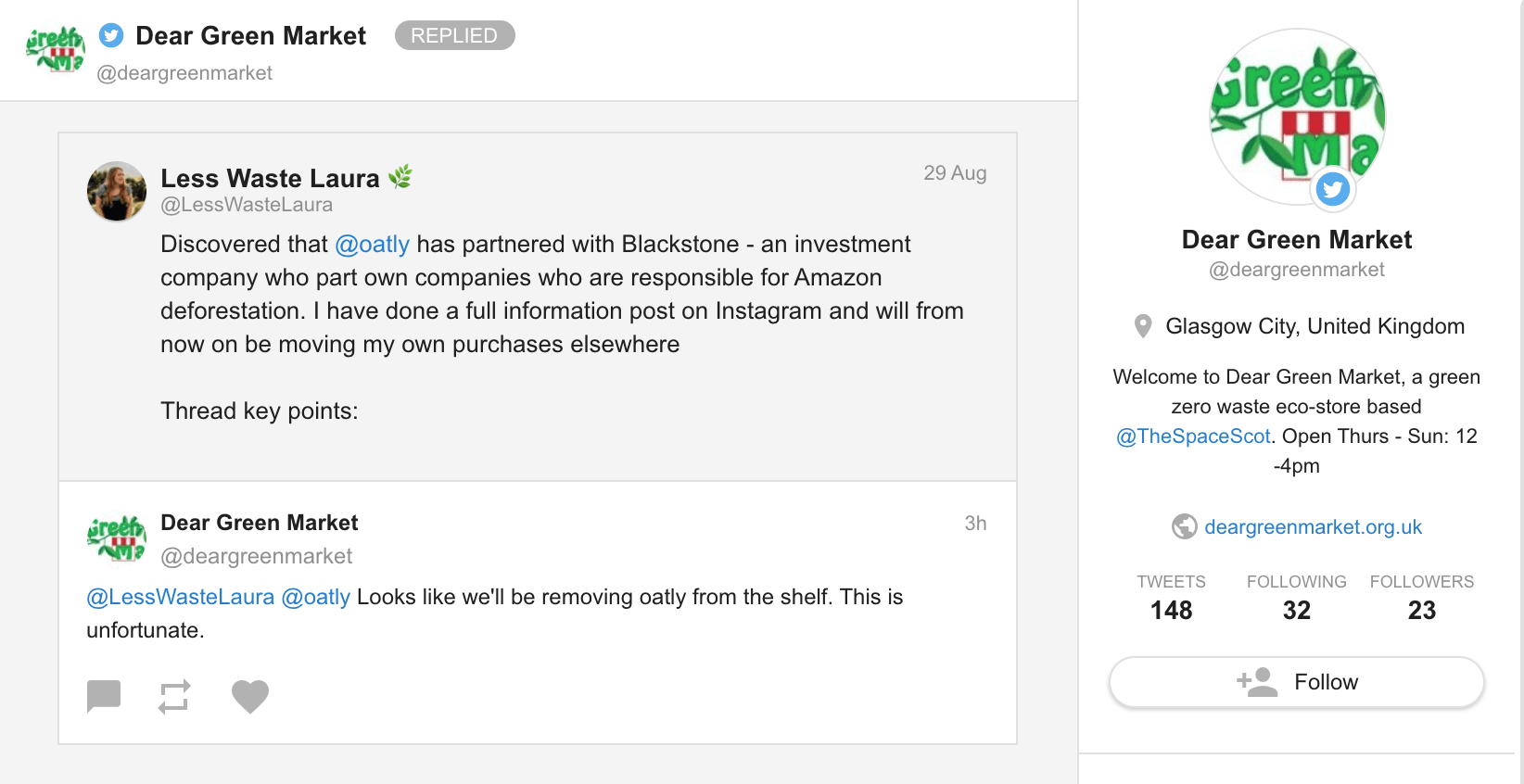
Monitoring customer sentiment and understanding how they feel about your products or services can also help your Customer Support team prioritize their work.
Make sure to address mentions containing negative words about your brand (particularly those with a higher reach) first — in Awario, you can do that by using filters in your mentions feed.
If you catch these negative conversations on social networks early, chances are you can turn the situation around for this specific client, and improve the customer experience for other consumers. Monitoring insights about customer sentiments, and feedback is an important part of a business. Invest in tools like contact center software, sentiment analysis tools and monitoring tools that help in crucial decision making process.
By signing up I agree to the Terms of Use and Privacy Policy
How does sentiment analysis work?
In data science lingo, sentiment analysis is a classification problem: the algorithm is presented with pieces of text that need to be classified as positive, negative, or neutral. The problem is usually tackled with the help of Natural Language Processing (NLP) in one of these three ways: supervised machine learning, rule-based techniques, or a combination of the two approaches.
Let's take a look at each of these sentiment analysis models.
1. Supervised machine learning (ML)
In supervised machine learning, the system is presented with a full set of labeled data for training. This dataset consists of documents whose sentiment has already been determined by human evaluators (data scientists). The computer then learns the sentiment analysis classifiers of the document from the training set and labels new input data (the test set).
In other words, using ML enables you automate low-level functions for text analyzing that sentiment analysis relies on.
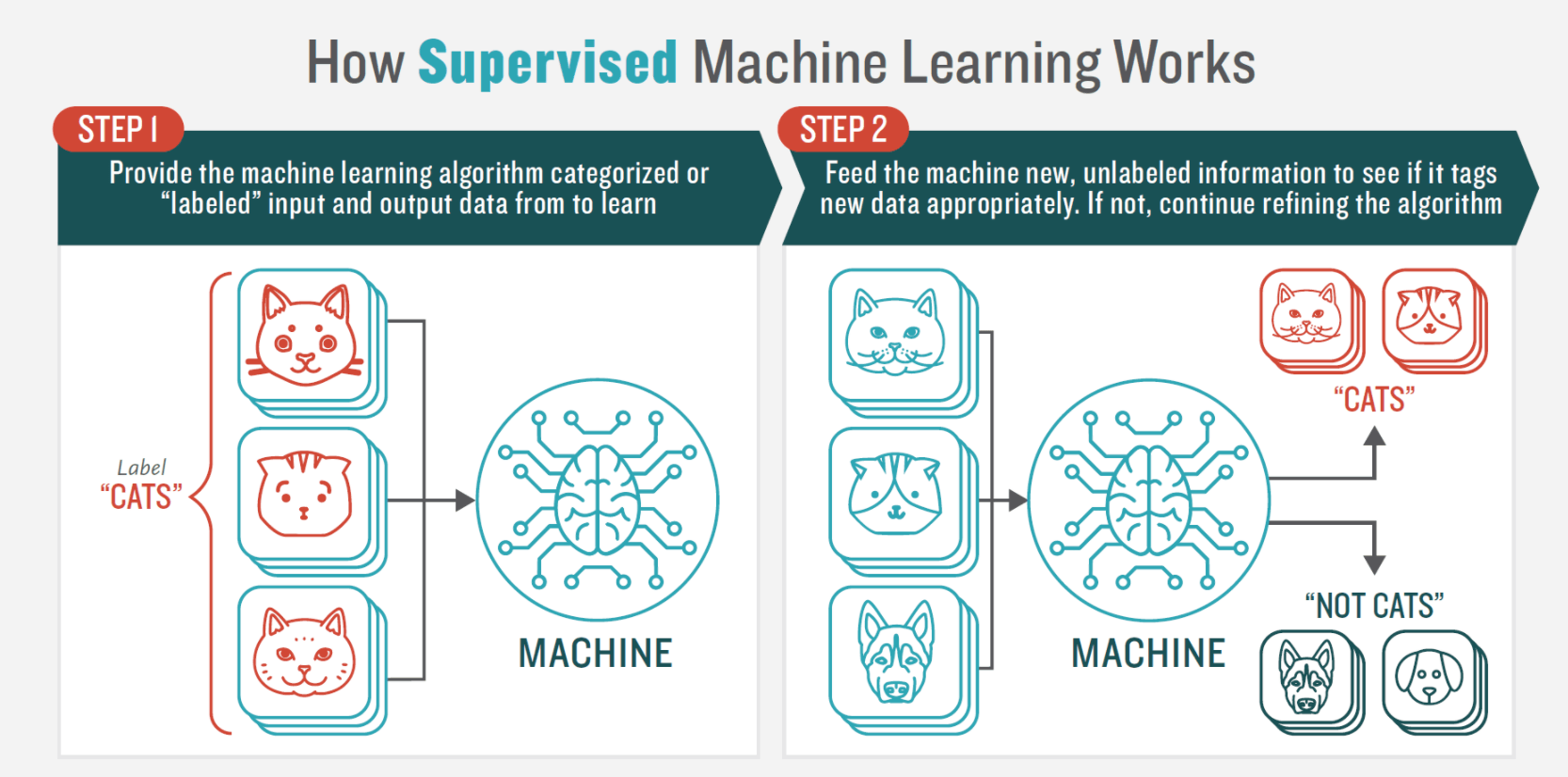
Various classification algorithms and neural networks can be used at this sentiment analysis model, such as Naive Bayes, logistic regression, Support Vector Machines, and others.
Regardless of the approach, the system will usually assign a score to all topics, categories, words and phrases in the text it's analyzing to reflect its sentiment: say, on a scale from -1 for 'extremely negative' to 1 for 'extremely positive'. These scores will then be added up for all words in the text and divided by the number of words in it to get the average score.
From there, it is up to the researcher to set the particular boundaries. For instance, you could say that an overall score between -1 and -0.33 should mean the statement is negative, use -0.33 to 0.33 for neutral, and 0.33 to 1 for positive.
Pros: Supervised machine learning techniques allow for creating trained models tailored for the specific purpose of the data analysis.
Cons: These models will often have poor adaptability between domains or different writing styles.
2. Rule-based methods
A rule-based system uses a set of human-crafted (and optionally machine-enriched) rules for text analysis. These rules commonly include sentiment lexicons (i.e. dictionaries of pre-labeled words and expressions).
Here’s a very basic example of what a dictionary may look like:
| Word | Sentiment score |
|---|---|
| Fantastic | 1 |
| Good | 0.5 |
| Okay | 0 |
| Bad | -0.5 |
| Terrible | -1 |
Once the system's at work, the first step is to look for words from the dictionary in the text it's analyzing (entity extraction).
From there, the maths is the same as with machine learning models: add up the scores for every word and divide the result by the number of words to get the average.
Lastly, determine the sentiment of the text based on the boundaries you set for positive, negative, and neutral.
Let's take the following sentence as an example:
The coffee was okay, but the food was terrible.
Since this text contains two words from our dictionary, the score would be:
(0 + (-1)) / 2 = -1 / 2 = -0.5
If you decided that a score between -1 and -0.33 means the statement is negative, there you have it — this sentence will be labeled as negative by the system.
Pros: Building rule-based systems is easier than deploying ML techniques, and they are often not so resource-heavy as machine learning algorithms. They also give the researcher full control over the vocabulary and can therefore have better term coverage.
Cons: Basic rule-based systems look at individual words or phrases and not how they are used in a sequence. Adding new rules may help, but eventually, the whole system can get very complex. On top of that, the number of words in dictionaries is finite, which may make problems for natural language processing in dynamic environments (I'm looking at you, social media). In other words, the lexicon-based technology will often require continuous fine-tuning.
3. Hybrid approaches
Sometimes, software developers combine supervised machine learning and lexicon-based approaches to improve sentiment accuracy without sacrificing performance. Enterprise software development positions itself as a pivotal means to tackle the challenges head-on with hybrid approaches. By strategically integrating machine learning algorithms with human oversight, companies can tap into deeper layers of data and decipher the complexities of human emotions with greater precision.
The techniques can be used alongside each other in different ways, but most commonly, a rule-based system (which is typically faster than ML algorithms) will attempt to classify the sentiment of a statement. If a certain degree of confidence is not achieved (e.g., when few or no words from the sentence are available in the lexicon), a machine learning classifier will be used to identify the sentiment of the statement.
Pros: Hybrid approaches can have the perks of both rule-based and machine learning methods, helping companies that use these kinds of sentiment analysis gain better marketing insights. They can have the perfomance benefits of lexicon-based techniques most of the time, but surpass them in accuracy to account for statements whose sentiment can't be easily identified with a rule-based approach.
Cons: Naturally, these systems take the most time and effort to build.
4. Support for every language
You read that right - the sentiment algorithm works for each and every language out there! We've done extensive testing for the languages that are most popular with Awario users (English, French, Spanish, German, and Portuguese) as well as smaller tests for other languages, and are happy to say that the accuracy of sentiment analysis for no language falls below 65%.
How accurate is sentiment analysis?
The accuracy of sentiment analysis is a term used to refer to how much of a sentiment analysis system's output agrees with human evaluations.
However, it's not as straightforward as it seems — research shows that human raters will only agree with each other between 65% and 80% of the time.
To follow the statement, you can paraphrase this to say:
The sentiment analysis accuracy of the human brain is between 65% and 80%.
Sentiment is often subjective, which makes it hard to measure accuracy. On average, researchers agree that a sentiment analysis system needs to be at least 50% accurate to be considered effective; an accuracy of over 65% is considered good, even if it may not sound impressive.
Awario, with its sentiment analysis accuracy of just over 70%, is doing nearly as well as humans.
There's also another reason why accuracy isn't always the ultimate way to measure how good an algorithm is.
Here's a great example of when it's not (unrelated to sentiment analysis):
Would you believe someone who claimed to create a model entirely in their head to identify terrorists trying to board flights with greater than 99% accuracy? Well, here is the model: simply label every single person flying from a US airport as not a terrorist. Given the 800 million average passengers on US flights per year and the 19 (confirmed) terrorists who boarded US flights from 2000–2017, this model achieves an astounding accuracy of 99.9999999%! That might sound impressive, but I have a suspicion the US Department of Homeland Security will not be calling anytime soon to buy this model. While this solution has nearly-perfect accuracy, this problem is one in which accuracy is clearly not an adequate metric!
The two other factors that tell the researchers how good their algorithm is are precision and recall.
Precision is the percentage of instances correctly identified as X by the system among all instances identified as X by the system.
Recall, on the other hand, is the ratio of the number of instances of X correctly identified by the system to all instances of X in the dataset.
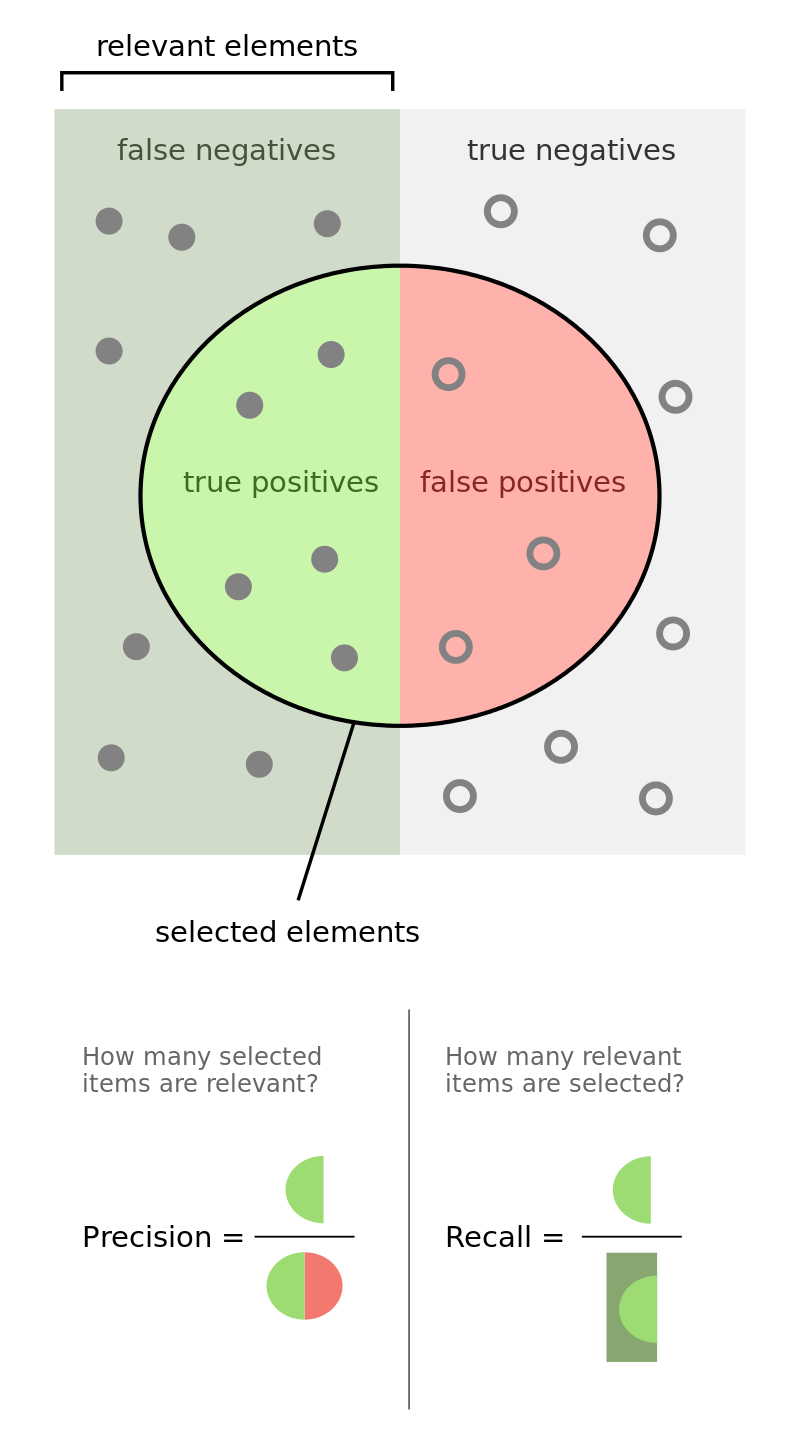
For instance, imagine we have a dataset of 10 statements: 7 of those are labeled by human experts as positive, and 3 as negative.
A sentiment analysis system identifies 5 statements as positive. Of these 5 instances, only 3 are actually positive (as evaluated by human experts).
The system's precision is 3/5 while its recall is 3/7.
What are the caveats of sentiment analysis?
We've seen that sentiment analysis is tricky even for humans, let alone machines — but why? Here are the biggest challenges sentiment analysis systems face (this is true for all languages).
1. Sarcasm

Any kind of natural language processing is tricky for short documents, and sentiment analysis is no exception. Social media posts are generally shorter than other kinds of web content, such as news articles, which means there's often little context to work with. This is particularly important for statements that are sarcastic or ironic.
In many cases, sarcasm is pretty obvious to people, but extremely tricky to detect for machines.
Here's an example:
It only took me 5 minutes to get a coffee at Starbucks. Great start of the day!
It only took me 30 minutes to get a coffee at Starbucks. Great start of the day!
2. Negations
Negations are a linguistic means of reversing the meaning of words, phrases, and even entire sentences. For the purposes of sentiment analysis, it is important not only to identify negation, but also to figure out which words are affected by it so that the system can revert their sentiment.
Like sarcasm, negation is pretty easy to interpret for humans, but it can be quite challenging for computers.
I wouldn't say the coffee was particularly good.
To deal with negation, sentiment classification algorithms will often revert the sentiment of all words starting with the negation word and up to the next punctuation mark. However, this approach can sometimes fail, as you can see in the example below.
I was hoping the coffee would be great. It wasn't.
3. Ambiguity
Emotional words, such as love and hate, are easy to interpret to both humans and machines. However, some words can be negative in one context, and neutral or positive in another, such as in the example below.
I tend to drink ice cold coffee in the summer.
When I finally got my coffee, it was ice cold.
4. Multipolarity
Oftentimes, the text you're analyzing will express several emotions at once. When you're presented with text that expresses one emotion towards one object or topic, and a different emotion towards another one, you are dealing with multipolarity.
Starbucks coffee is much better than Dunkin'.
(Shameless plug: if you're wondering which really is better, head to our social listening analysis of the two brands.)
In this case, a basic opinion mining system might conclude the sentiment of the statement is positive, based off of the phrase much better. However, if the brand you're monitoring is Dunkin', I bet you wouldn't agree. To deal with multipolarity, an approach called aspect-based sentiment analysis is used.
Did you draw any conclusions from what you read?
I hope this guide provided direct insight into sentiment analysis, its uses, and challenges. For a brief instant, you could think that it’s hard to use or it’s useless for marketers at all. However, depending on your goals, you can adapt sentiment analysis to your daily marketing routine easily.
Still have questions about sentiment? Please let us know! Go to our social pages to leave your comments and ask your questions there.


